
从“5,394%利润”到真正稳健的机器学习系统
如果你在在线交易的世界里待过一段时间,你一定见过它们:宣称用“秘密”指标组合即可获得惊人收益的文章和视频。他们拿像 TSLA 这样的热门股票做回测,权益曲线直冲云霄。
我们最近就看到了一篇这样的文章:“考夫曼自适应移动平均(KAMA)与 ATR 多头策略” 它提出了一个很有吸引力的想法:用自适应的 KAMA 做趋势跟随,用 ATR 做基于波动的风险控制。在 TSLA 上的结果惊人:5394% 的利润,远超买入并持有。
但作为经验丰富的工程师,我们知道,不凡的主张需要不凡的证据。因此我们提出了关键问题:这个策略能否经得起严格、专业的回测流程?
第 1 部分:不可避免的失望
我们的第一步,复现文章的基于规则的逻辑。规则很简单:
入场: 当价格在 KAMA 之上且波动(ATR 百分比)处于“平静”范围内。
出场: 当价格跌破 KAMA 或波动突然上行。
我们在 QQQ 上使用标准的步进前移(walk-forward)分析来运行它。与文章中对全量数据做一次性优化不同,这种方法通过在历史数据上训练、在未来未见数据上测试来模拟真实交易。
结果是……差强人意。该策略几乎不赚钱,夏普比率接近于零。
为什么差异如此之大?
过拟合陷阱: 原文在整段历史数据上优化了参数。这在量化金融里是大忌,称为曲线拟合。那些“完美”的参数是用完美的事后视角定制出来的,使结果完全不现实。
不现实的风控: 原始回测过于简化,很可能采用了“满仓”之类的做法。我们的框架强制实施纪律化的仓位控制与止损,把保住本金优先于追逐像彩票般的暴利。
挑拣样本: 文章突出展示了 TSLA、MSTR 等极端动量股。一个稳健的策略必须能在不同资产与不同市场环境下工作,而不是只在少数异类上好看。
结论很明确:按原样给出的基于规则的策略,并不适合真实世界的交易。
第 2 部分:转向机器学习
我们没有抛弃核心概念,而是选择转向。把自适应趋势(KAMA)与波动过滤(ATR)结合的思路本身是合理的,问题在于刻板、被过度优化的规则。
如果我们不再把规则写死,而是把这些指标作为特征,交给机器学习模型来学习呢?
这改变了我们的做法:
特征工程: 我们构建了一组归一化的特征来描述市场状态。
目标标注: 使用三重障碍法(Triple-Barrier Method)定义什么是“好”的交易。
训练模型: 借助 AlphaSuite 的集成机器学习流水线训练 LightGBM 模型,寻找制胜模式。
这个策略不再是一组脆弱的“if-then”语句,而是一个能够学习和适应的灵活系统。
关键在细节:核心计算
要真正理解这种转变,我们来看代码。从一个有缺陷的规则变成稳健的特征,涉及几个关键计算。
1. 构建稳健特征
最大的飞跃来自我们如何创建特征。对于学习长期数据的模型来说,原始指标值往往没什么用。例如,当一只股票价格为 50 美元时,MACD 为 2.00 是个很大的数,但当价格在 500 美元时,这个值就毫无意义。
我们通过对特征做归一化来解决这一问题,构建与价格水平无关的信号。
# 按价格对 MACD 进行归一化,使其在时间上可比
data['feature_macdhist'] = data['macd_hist'] / data['close']
# 将 RSI 缩放到一致的 0-1 区间
data['feature_rsi'] = data['rsi'] / 100.0
# 计算价格相对移动平均的百分比偏离
data['feature_price_kama_dist'] = (data['close'] / data['kama']) - 1
无论模型在看 2005 年还是 2025 年的数据,这都能为其提供一致的可学习信号。
2. 用“三重障碍法”定义“胜利”
我们如何教会模型什么是好交易?我们使用“三重障碍法”。对每一笔潜在交易,我们在未来设置三道“障碍”:
盈利目标(例如:平均真实波幅 ATR 的 3 倍)
止损(例如:平均真实波幅 ATR 的 3 倍)
时间限制(例如:15 天)
最先被触及的障碍决定结果。
# 标注交易的简化逻辑
profit_target = entry_price + (atr_at_entry * profit_target_multiplier)
stop_loss = entry_price - (atr_at_entry * stop_loss_multiplier)
# 向前查看 N 根K线
future_bars = data.loc[i:].iloc[1:eval_bars + 1]
# 检查是否触及盈利目标
pt_hit_mask = future_bars['high'] >= profit_target
pt_hit_date = future_bars.index[pt_hit_mask].min()
# 检查是否触及止损
sl_hit_mask = future_bars['low'] <= stop_loss
sl_hit_date = future_bars.index[sl_hit_mask].min()
# 只有当先触及盈利目标且早于止损触发时,才算胜利。
if pd.notna(pt_hit_date) and (pd.isna(sl_hit_date) or pt_hit_date < sl_hit_date):
target.loc[i] = 1.0 # 胜利
else:
target.loc[i] = 0.0 # 亏损(止损或超时)第3部分:结果——从炒作到真实优势
我们用同样严格的步进前移优化在 QQQ 上运行了新的机器学习策略。结果判若云泥。
夏普比率: 稳健的 0.90
样本外总回报: 376%
最大回撤: 非常可控的 16.4%
有趣的是,当我们做一次性“样本内”回测(在整整 25 年期间用一套优化后的参数)时,该策略的回报为 791%,轻松击败同期买入持有的 631%。这说明在参数相对稳定的设定下,策略具有理论潜力。
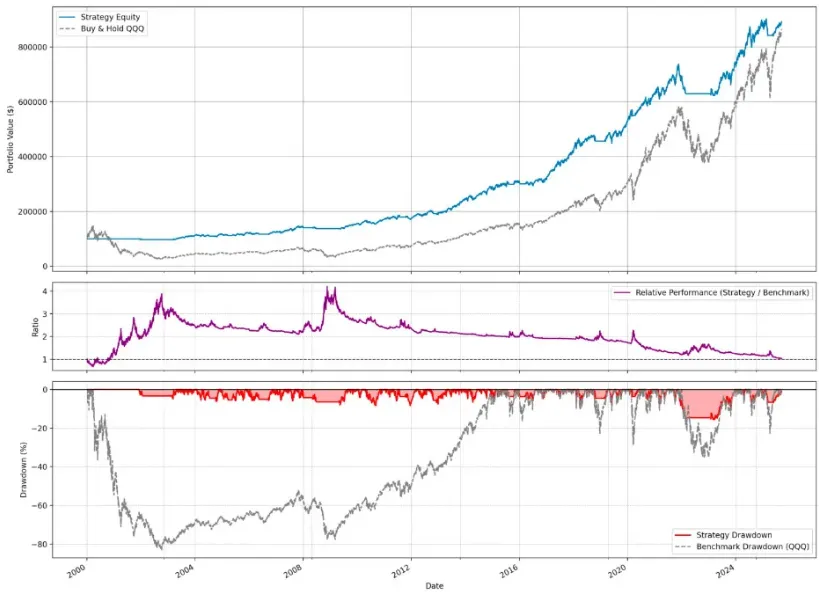
不过,更加贴近现实的 376% 样本外回报 才是我们信任的数字。虽然它在测试期内不如完美事后视角下的买入持有,但它以更小的风险实现了这一点。它成功躲过了主要的市场下行,而被动投资者可能会遭遇毁灭性的损失。这正是专业策略设计的核心权衡:以牺牲部分潜在上行,换取风险的大幅降低。
而最有意思的洞见来自特征重要性图,它告诉我们模型认为哪些最重要:
feature_atr_pct(重要性最高): 模型最关键的因素是市场波动。它学会了高度选择性,这以数据驱动的方式印证了原文的核心观点。
feature_price_sma200_dist: 长期趋势过滤器排在第二,说明模型学会了不与主要趋势作对。
feature_macdhist: MACD 柱(衡量动量加速度)在择时中也被高度重视。
模型验证了初始概念,但找到了更加细致且稳健的执行方式。
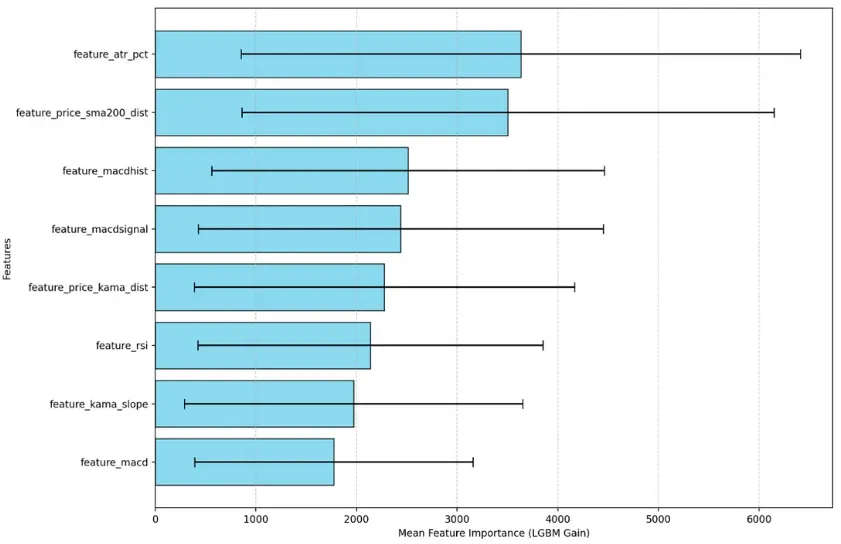
跨折平均的特征重要性
停止曲线拟合,才是构建策略的开始
从一个有缺陷的基于规则的策略,到一个稳健的机器学习系统,这段旅程凸显了现代量化研究的核心原则:
保持怀疑: 对“完美”的回测保持高度警惕。
严格测试: 步进前移分析与现实的风险管理是不可妥协的。
迭代与适应: 不要害怕从僵硬的想法转向更灵活、数据驱动的方法。。